Algorithms that construct ensemble models from data sets with hierarchical class
The algorithms construct random forest ensembles of predictive clustering trees (PCTs). PCTs are generalization of popular decision trees. Similar to a decision tree model, a PCT model is composed of nodes that represent attributes and leaves that represent class labels. In addition, a PCT leaf can represent multiple interconnected class labels.
The five algorithms represent class in different manner and construct different number of ensembles. Accordingly, they are divided in three groups:
-
Baseline algorithm constructs a single ensemble of PCTs. Each PCT leaf represents the complete hierarchy. When classifying a new example, each label in the hierarchy receives a probability that it is associated with the example. The probabilities are calculated according the leaf that the example reached. The algorithm enforces the hierarchy constraint, which ensures that children labels do not have probabilities higher than those of their parents.
-
Partial hierarchy decomposition algorithms construct multiple ensembles. Each ensemble predicts a sub-hierarchy. Algorithms in this group are Child vs. parent label and Label specialization.
-
Complete hierarchy decomposition algorithms construct one or multiple ensembles. The algorithms ignore hierarchy over labels and predict only the most specific labels in paths associated with data set examples. Algorithms in this group are Labels without hierarchical relations and Label vs. the rest.
Partial hierarchy decomposition algorithms
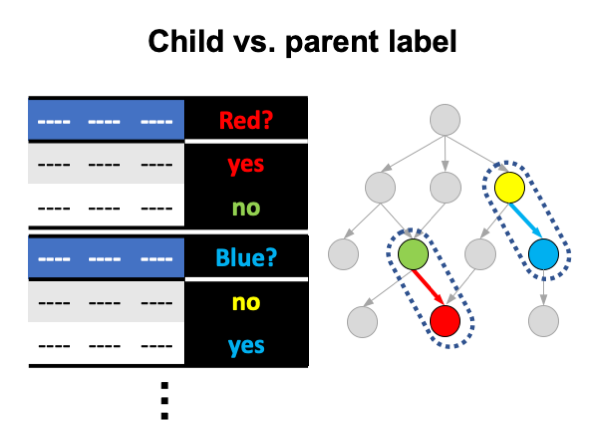
Child vs. parent label
The algorithm constructs an ensemble for each child-parent pair in the hierarchy by following the steps:
- For each non-root label l:
- Construct a training set composed only of examples labeled with the parent of l;
- Relabel examples in the training set: those labeled with l as positive, and the rest as negative;
- Construct an ensemble from the training set.
A new example is classified with all of the ensembles. A PCT leaf that the example reaches contains a probability of label l knowing its parent. The probabilities from multiple ensembles are pulled together and hierarchy constraint is applied on them.
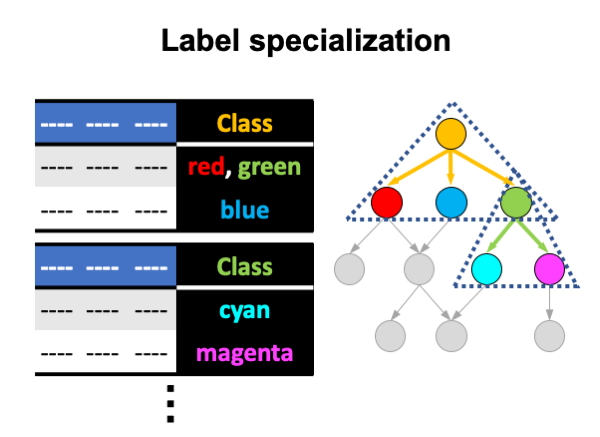
Label specialization
The algorithm constructs an ensemble for each non-leaf node in the hierarchy. The ensemble differentiates among children nodes. Steps:
- For each non-leaf label l:
- Construct a training set composed only of examples labeled with l;
- Label examples in the training set with children labels of l. An example can have multiple labels;
- Construct an ensemble from the training set.
A new example is classified with all of the ensembles. A PCT leaf that the example reaches contains probabilities of children labels knowing their parent. The probabilities from multiple ensembles are pulled together and hierarchy constraint is applied on them.
Complete hierarchy decomposition algorithms
The most specific labels
A set of the most specific labels is obtained by following the steps:
- For each example in a data set:
- For each path associated with the example:
- Add to the set the most specific label in the path.
- For each path associated with the example:
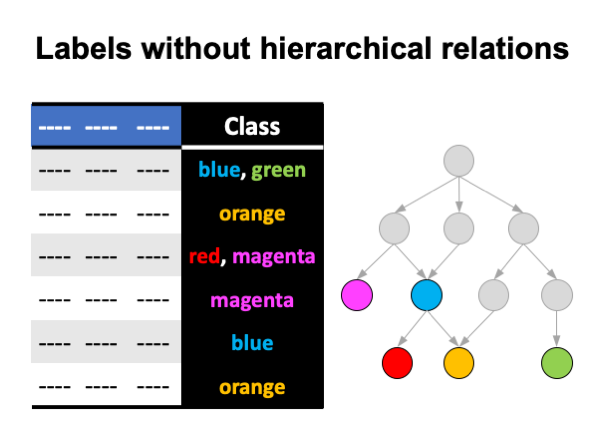
Labels without hierarchical relations
The algorithm constructs an ensemble that differentiates among the most specific labels. Steps:
- Remove the labels that do not qualify as the most specific labels from the training set.
- Construct an ensemble from the training set.
When classifying a new example, a PCT leaf that the example reaches contains probabilities that the example is associated with each of the most specific labels. Probabilities for inner labels are zero.
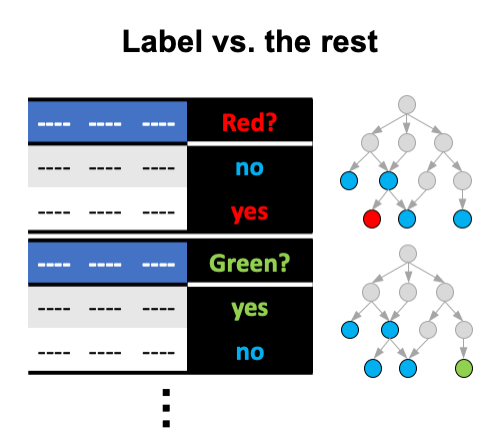
Label vs. the rest
The algorithm constructs an ensemble for each of the most specific labels. Each ensemble differentiates between a specific label and all the other labels in the training set. Steps:
- For each most specific label l:
- Construct a training set with all training examples;
- Relabel examples as positive if they are labeled with l and as negative otherwise;
- Construct an ensemble from the training set.
A new example is classified with all of the ensembles. A PCT leaf that the example reaches contains a probability that the example is associated with the label l. The probabilities from multiple ensembles are pulled together. Probabilities for inner labels are zero.
Why the pipeline implements five algorithms?
Data sets with hierarchical class differ:
- Hierarchical class differs in shape, size and complexity;
- Examples can be associated exclusively with a single path (hierarchical single-label classification) or with multiple paths (hierarchical multi-label classification) from the hierarchy.
Accordingly, there is no single best performing algorithm. For example:
- When the hierarchy is large (100 labels or more) and complex (parents labels have on average three or more children labels), algorithms that exploit hierarchical structure (baseline and partial decomposition algorithms) outperform the complete decomposition algorithms.
- When examples are associated solely with single paths, which always end with hierarchy leaf labels, Label vs. the rest algorithm outperforms the other algorithms. In this case, hierarchical structure over labels introduces unnecessary noise to the model induction process.
In many cases it is not clear which algorithm will outperform the others. Therefore, the pipeline implements the five algorithms and the tool that compares their predictive performance in cross-validation.
Further reading
-
PCTs are explained in the paper:
Vens C., Struyf J., Schietgat L., Džeroski S., Blockeel H. (2008) Decision Trees for Hierarchical Multi-label Classification. Machine Learning, 73, 185-214. https://doi.org/10.1007/s10994-008-5077-3 -
The five algorithms that construct ensemble models from data sets with hierarchical class are explained in the paper:
Vidulin V., Džeroski S. (2020) Hierarchy Decomposition Pipeline: A Toolbox for Comparison of Model Induction Algorithms on Hierarchical Multi-label Classification Problems. In: Appice A., Tsoumakas G., Manolopoulos Y., Matwin S. (eds) Discovery Science. DS 2020. Lecture Notes in Computer Science, vol 12323. Springer, Cham. https://doi.org/10.1007/978-3-030-61527-7_32